
Reverse Engineering iWork
So you don't have to.

The app I’m working on ingests a lot of files, and there’s no good solution for parsing .key, .numbers, or .pages files. Every existing approach requires you to first export your document to PDF (or some other format), then upload it for server-side processing. At that point, you’re either running it through a vision model or a PDF parser, both of which lose significant information or don’t work particularly well.
This isn’t my first time solving distribution problems by going directly to the source. I previously ported Perl to WebAssembly so ExifTool could run client-side for metadata extraction, avoiding the need to upload files or have Perl installed. Same principle applies here: if you want high-quality extraction from iWork files without round-tripping through export formats or sending data to a server, you need to parse the native format.
I am not held back by the conventional wisdom for the simple reason that I am completely unaware of it. So I decided to build a proper parser that keeps user files on their computer and produces the highest quality output possible.
A Brief History of iWork
In 2013, Apple switched the iWork document format from XML1 to a new binary format built on Google’s Protocol Buffers. The change affected Pages, Keynote, and Numbers, and coincided with iCloud support for iWork and the transition to 64-bit applications. Apple never publicly explained the decision, but the old XML format, which loaded entire documents and assets into memory at once, would have made it difficult to deliver a good experience on the early iPhone, iPad, and web.
Finding the Descriptors
Apple ships Pages, Keynote, and Numbers with their protobuf message descriptors preserved in the executables. These descriptors define the structure of every message type and can be recovered from the binaries.
The recovery process works by scanning through the binary data looking for specific patterns. Protocol Buffer descriptors have a recognizable structure: they start with a length-delimited field (tag 0x0A) followed by a varint length and then the filename, which always ends in .proto. Once we find a potential descriptor, we validate it by reading through the protobuf wire format:
// Search for ".proto" filename suffix in binary data
let protoSuffix = ".proto".data(using: .utf8)!
let protoStartMarker: UInt8 = 0x0A // Protobuf wire format tag
// When we find ".proto", scan backwards for the start marker
let markerIndex = findMarkerBackwards(
in: data,
to: suffixRange.lowerBound,
marker: protoStartMarker
)
// Read the filename length as a varint and verify
var nameLength: UInt64 = 0
guard readVarint(&nameLength, from: data, offset: markerIndex + 1) else {
continue
}After validating the descriptor start, we need to find where it ends. Descriptors terminate with a null tag (tag value of 0), so we read through the wire format until we hit that marker:
let stream = ProtobufInputStream(data: potentialDescriptorData)
let descriptorLength = stream.readUntilNullTag()The readUntilNullTag() method handles the various protobuf wire types; varints, fixed-width integers, and length-delimited data—advancing through the stream until it encounters the terminating null tag.
Converting Descriptors to Source
Swift’s protobuf library doesn’t include a built-in mechanism for converting descriptors back into human-readable .proto files. The C++ library has this feature, but we’re working with Swift here. Fortunately, SwiftProtobuf provides a visitor API that lets us traverse the descriptor structure and reconstruct the schema ourselves.
The visitor pattern walks through each field in the descriptor:
struct ProtoRenderer: SwiftProtobuf.Visitor {
private var output: [String] = []
mutating func visitRepeatedMessageField<M: Message>(
value: [M],
fieldNumber: Int
) throws {
switch fieldNumber {
case 4: // Message definitions
for msg in value {
try renderMessage(msg)
}
case 5: // Enum definitions
for enumMsg in value {
try renderEnum(enumMsg)
}
case 6: // Service definitions
for svc in value {
try renderService(svc)
}
}
}
}When we visit string fields, we capture the syntax version and package name. When we visit repeated message fields with specific field numbers (4, 5, 6), we know we’re looking at message definitions, enum definitions, or service definitions. Each gets rendered with proper indentation and syntax:
private mutating func renderMessage(_ desc: DescriptorProto) throws {
emit("message \(desc.name) {")
indent += 1
for field in desc.field {
let label = fieldLabel(for: field.label) // optional, required, repeated
let type = fieldType(for: field.type) // int32, string, etc.
emit(”\(label)\(type) \(field.name) = \(field.number);”)
}
indent -= 1
emit("}")
}Apple’s Object-Oriented Protobuf System
Once we dump the schemas, we can see how Apple structured their system. In typical Apple fashion, they built an entire object-oriented layer on top of protobufs. The format includes inheritance hierarchies (messages have “supers”), reflection capabilities, and a type system that clearly took inspiration from the Objective-C runtime it was designed to interface with.
Consider how a typical message is defined:
message TSDDrawableArchive {
optional .TSP.Reference super = 1;
optional .TSD.FillArchive fill = 10;
optional .TSD.StrokeArchive stroke = 11;
// ... more fields
}That super field isn’t standard protobuf; it’s Apple’s way of encoding inheritance. The TSP.Reference type points to another message, effectively creating a parent-child relationship between objects. This mirrors how Objective-C class hierarchies work, with each object maintaining a reference to its superclass.
Mapping Types to Prototypes
Having the schemas is only half the battle. Each message in an iWork Archive (IWA) includes a type identifier; an integer that tells the parser which protobuf message definition to use. We need to build a mapping from these type IDs to their corresponding Swift classes.
Apple stores this mapping in a runtime registry called TSPRegistry. We can extract it using Frida:
var TSPRegistry = ObjC.classes.TSPRegistry;
var registry = TSPRegistry.sharedRegistry();
// The registry’s description includes the type-to-prototype mappings
var description = registry.toString();
var lines = description.split("\n");
for (var line of lines) {
if (line.includes(" -> ")) {
var [typeNum, className] = line.split(" -> ");
results[parseInt(typeNum)] = className.trim();
}
}This gives us a JSON mapping like:
{
"1": "TSPArchiveInfo",
"2": "TSPDataInfo",
"10000": "TSDDrawableArchive",
"11000": "TSTTableDataList"
}With this mapping in hand, we can generate Swift decoder functions that translate type IDs to the appropriate message classes. We also need to handle extensions—some messages use protobuf extensions for additional fields. By scanning the generated Swift code, we build a secondary map of which extensions apply to which messages:
# Find MessageExtension declarations in Swift files
extension_pattern = r’static\s+let\s+(\w+)\s+=\s+MessageExtension<[^,]+,\s*(\w+)>’
# Example match:
extension TSA_ThemePresetsArchive {
enum Extensions {
static let `extension` = SwiftProtobuf.MessageExtension<SwiftProtobuf.OptionalMessageExtensionField<TSA_ThemePresetsArchive>, TSS_ThemeArchive>(
_protobuf_fieldNumber: 210,
fieldName: "TSA.ThemePresetsArchive.extension"
)
}
}Then we generate decoders that automatically include the right extensions:
func decodeKeynote(type: UInt32, data: Data) throws -> SwiftProtobuf.Message {
switch type {
case 10000:
return try TSDDrawableArchive(
serializedBytes: data,
extensions: SimpleExtensionMap([
TSDArchive.Extensions.geometry,
TSDArchive.Extensions.externalTextWrap
])
)
// ... more cases
}
}Parsing the IWA Format
With the schemas extracted, the type mappings generated, and the decoders built, we have everything needed to parse iWork documents.
Document Structure
An iWork document comes in two physical formats: a directory bundle or a ZIP archive. Both contain the same logical structure:
Document.pages/
├── Index.zip # Contains all .iwa files
├── Metadata/
│ ├── Properties.plist
│ ├── DocumentIdentifier
│ └── BuildVersionHistory.plist
├── Data/ # Referenced media files
│ ├── image-123.jpeg
│ └── video-456.mp4
└── preview.jpg # Document thumbnailThe Index.zip archive (or Index/ directory in bundle format) contains the actual document structure as a collection of IWork Archives. Each IWA holds a series of compressed protobuf messages that represent different parts of the document.
Snappy Compression
IWA use Snappy compression, however, Apple’s implementation diverges from the standard Snappy framing format. Traditional Snappy includes CRC32 checksums for data integrity; Apple’s version drops these entirely.
Initially, I wrapped the C Snappy library, but this made Swift build times incredibly long. After examining the format more carefully, I realized Apple’s simplified approach meant I could write a pure Swift implementation:
private static func decompressSnappyChunks(_ data: Data) throws -> Data {
var result = Data()
var offset = 0
while offset < data.count {
// Apple’s custom header: single byte (always 0) + 3-byte length
let headerType = data[offset]
guard headerType == 0 else {
throw IWorkError.invalidIWAHeader(expected: 0, found: headerType)
}
offset += 1
// Read 24-bit little-endian length
let length = Int(data[offset])
| (Int(data[offset + 1]) << 8)
| (Int(data[offset + 2]) << 16)
offset += 3
let compressedChunk = data.subdata(in: offset..<offset + length)
offset += length
let decompressed = try decompressSnappy(type: headerType, data: compressedChunk)
result.append(decompressed)
}
return result
}The Snappy decompression itself follows the standard algorithm: reading literal bytes and copy operations from a backreference buffer. The format uses two-bit tags to distinguish between literals (tag 0) and copies of varying offsets (tags 1-3):
while offset < data.count {
let tag = data[offset] & 0x3
if tag == 0 {
// Literal: copy bytes directly
var len = Int(data[offset] >> 2) + 1
offset += 1
// Handle variable-length encoding for longer literals
if len > 60 {
let extraBytes = len - 59
len = readMultiByteLength(from: data, at: offset, bytes: extraBytes)
offset += extraBytes
}
chunks.append(data.subdata(in: offset..<offset + len))
offset += len
} else {
// Copy: reference previous data
let (copyOffset, length) = decodeCopyOperation(tag, from: data, at: &offset)
chunks.append(copyFromBackreference(offset: copyOffset, length: length))
}
}IWA Structure
After decompression, an IWA contains a sequence of archive chunks. Each chunk starts with a varint specifying its length, followed by a TSP.ArchiveInfo protobuf message:
var offset = 0
while offset < decompressed.count {
// Read length prefix
guard let (length, bytesRead) = readVarint(from: decompressed, at: offset) else {
break
}
offset += bytesRead
// Parse ArchiveInfo metadata
let chunk = decompressed.subdata(in: offset..<offset + length)
let archiveInfo = try TSP_ArchiveInfo(serializedBytes: chunk)
offset += length
// Process contained messages...
}The ArchiveInfo message describes what follows: one or more protobuf messages, each with a type ID and length. The structure looks like this:
message ArchiveInfo {
required uint64 identifier = 1;
repeated MessageInfo message_infos = 2;
optional bool should_merge = 3;
}
message MessageInfo {
required uint32 type = 1;
required uint32 length = 3;
}The actual message payloads follow immediately after the ArchiveInfo:
for messageInfo in archiveInfo.messageInfos {
let payloadLength = Int(messageInfo.length)
let payload = decompressed.subdata(in: offset..<offset + payloadLength)
offset += payloadLength
// Decode using our generated type map
let message = try decodePayload(
payload,
type: messageInfo.type,
documentType: documentType
)
records[archiveInfo.identifier] = message
}Two-Pass Loading for Message Merging
One interesting aspect of IWA format is its support for incremental updates. Some archives have a should_merge flag set, indicating that their messages should be merged with existing records rather than replacing them. This allows iWork to efficiently save only the changed parts of a document.
The parser handles this with a two-pass system:
// First pass: load all non-merge messages
for path in iwaPaths {
let data = try storage.readData(from: path)
try loadIWA(data, into: &records, mergingOnly: false)
}
// Second pass: merge incremental updates
for path in iwaPaths {
let data = try storage.readData(from: path)
try loadIWA(data, into: &records, mergingOnly: true)
}During the merge pass, if a record already exists, we use SwiftProtobuf’s merge functionality to combine the messages:
if archiveInfo.shouldMerge {
if var existingMessage = records[identifier] {
try existingMessage.merge(serializedBytes: payload)
records[identifier] = existingMessage
} else {
// First encounter of this ID in merge pass—treat as new
records[identifier] = try decode(payload, type: messageInfo.type)
}
}This merging system is particularly useful for collaborative editing scenarios where multiple users might be making changes simultaneously; only the delta needs to be transmitted and merged into the existing document structure.
Traversing Document Content
With the IWAs decoded and all protobuf messages loaded into memory, we now have a dictionary mapping record identifiers to their parsed messages. We now need to understand how these records reference each other to form the actual document structure.
One Format, Three Applications
Pages, Keynote, and Numbers all share the same underlying IWA format, but each application structures its content differently. Pages documents have a body storage with flowing text and floating drawables. Keynote presentations organize content as a sequence of slides, each with positioned elements. Numbers spreadsheets group content into sheets containing tables and supporting visuals.
Despite these organizational differences, the fundamental building blocks are identical. All three applications use the same message types for text storage, images, shapes, and tables. The parser needs to handle these application-specific structures while sharing code for the common elements.
The document record (always ID 1) tells us which application we’re working with:
switch document.type {
case .pages:
// Body storage with inline and floating elements
guard let bodyStorage: TSWP_StorageArchive = document.dereference(docArchive.bodyStorage) else {
return
}
try await traverseStorage(bodyStorage, ...)
case .keynote:
// Slides with positioned drawables
for slideID in slideIDs {
guard let slide: KN_SlideArchive = document.record(id: slideID) else { continue }
for drawableRef in slide.drawablesZOrder {
try await traverseDrawable(drawableRef, ...)
}
}
case .numbers:
// Sheets containing tables and other elements
for sheetRef in docArchive.sheets {
guard let sheet: TN_SheetArchive = document.dereference(sheetRef) else { continue }
for drawableRef in sheet.drawableInfos {
try await traverseDrawable(drawableRef, ...)
}
}
}Images
Images live in TSD_ImageArchive messages and reference their actual image data through a data ID that maps to a file in the Data/ directory:
guard let dataID = parseDataID(from: image),
let metadata: TSP_PackageMetadata = document.record(id: 2),
let resolvedFile = resolveFile(from: metadata, dataID: dataID),
let filename = resolvedFile.0,
let filepath = resolvedFile.1 else {
return nil
}Images include rich metadata: dimensions, captions, accessibility descriptions, and styling (borders, shadows, opacity, reflections). They can have masks that define their visible shape, like a star-shaped mask on a rectangular photo. The mask has its own geometry that we need to parse separately:
let imageGeometry = image.super.geometry
let maskGeometry = maskArchive.super.geometry
// Calculate transform from image to mask coordinate space
let imageOffset = CGPoint(
x: CGFloat(imageGeometry.position.x - maskGeometry.position.x),
y: CGFloat(imageGeometry.position.y - maskGeometry.position.y)
)
let imageScale = CGSize(
width: maskGeometry.size.width > 0
? CGFloat(imageGeometry.size.width / maskGeometry.size.width) : 1.0,
height: maskGeometry.size.height > 0
? CGFloat(imageGeometry.size.height / maskGeometry.size.height) : 1.0
)Before properly implementing protobuf extensions, I ran into some interesting discoveries. Web videos (embedded YouTube/Vimeo content) appeared to be just images with hyperlinks; I could see the thumbnail (because it was the image) and the URL in its parent, but none of the video-specific attributes. Turns out these attributes lived in protobuf extensions that I wasn’t loading.Once I added extension support, suddenly all the remote video.
Media
One of my favorite quirks: audio files, video files, and 3D models all use the same TSD_MovieArchive message type. Apple distinguishes them through flags and extensions rather than separate message types:
private func parseMediaType(from movie: TSD_MovieArchive) -> MediaType {
if movie.audioOnly {
return .audio
}
if let dataID = parseMediaDataID(from: movie),
let fileInfo = resolveFile(from: metadata, dataID: dataID),
let filename = fileInfo.0 {
if filename.lowercased().hasSuffix(".gif") {
return .gif
}
}
return .video
}
private func is3DObject(from movie: TSD_MovieArchive) -> Bool {
return movie.hasTSA_Object3DInfo_object3DInfo
}Audio, video, and GIF files share most of their metadata structure: duration, volume, loop options, poster images. 3D models get additional properties through an extension: pose information (yaw, pitch, roll), animation flags, bounding rectangles, and traced paths for text wrapping.
Video? TSD_MovieArchive. Music? TSD_MovieArchive. GIF?! TSD_MovieArchive. Photo Gallery? TSD_MovieArchive.3D Model? Believe it or not, TSD_MovieArchive
Equations
They’re stored in TSD_ImageArchive messages; technically they render as images in the document. Initially, I didn’t have protobuf extensions working, so I saw equation images, but no source data. I assumed Apple stored the LaTeX or MathML source in the PDF metadata stream, so I wrote a PDF parser:
package func extractMetadataFromPDF(with id: UInt64, using data: Data) throws -> IWorkEquation {
guard let dataProvider = CGDataProvider(data: data as CFData),
let document = CGPDFDocument(dataProvider),
let catalog = document.catalog else {
throw IWorkError.equationReadFailed(id: id, reason: "Failed to create PDF document")
}
var metadataObjectRef: CGPDFObjectRef?
guard CGPDFDictionaryGetObject(catalog, "Metadata", &metadataObjectRef) else {
throw IWorkError.equationReadFailed(id: id, reason: "No metadata object found")
}
var metadataStream: CGPDFStreamRef?
guard CGPDFObjectGetValue(metadataObjectRef!, .stream, &metadataStream) else {
throw IWorkError.equationReadFailed(id: id, reason: "Failed to get metadata stream")
}
var format = CGPDFDataFormat.raw
guard let rawData = CGPDFStreamCopyData(metadataStream!, &format) else {
throw IWorkError.equationReadFailed(id: id, reason: "Failed to copy metadata stream")
}
let metadataData = Data(bytes: CFDataGetBytePtr(rawData), count: CFDataGetLength(rawData))
guard let xmlString = String(data: metadataData, encoding: .utf8) else {
throw IWorkError.equationReadFailed(id: id, reason: "Failed to decode metadata")
}
return try parseEquationFromXML(with: id, from: xmlString)
}
package func parseEquationFromXML(with id: UInt64, from xmlString: String) throws -> IWorkEquation {
let regex = Regex {
"<equation><![CDATA["
Capture {
OneOrMore(.any, .reluctant)
}
"]]></equation>"
}
guard let match = xmlString.firstMatch(of: regex) else {
throw IWorkError.equationReadFailed(id: id, reason: "No equation CDATA found")
}
let equationContent = String(match.1)
if equationContent.contains("http://www.w3.org/1998/Math/MathML") {
return .mathml(equationContent)
} else {
return .latex(equationContent)
}
}This worked because Apple does embed the source in PDF metadata. But once I got extensions working properly, I discovered the equation source is right there in the IWA file as an extension field. All that PDF parsing code reduced to:
if let equation = image.equation {
return .equation(equation)
}Much better.
Tables
Tables are easily the most complex structures in the format. A TST_TableModelArchive contains the table’s structure and data, but the actual cell contents live in a compressed binary format within tile storage.
Tables are divided into tiles (typically 256x256 cells) to avoid loading massive spreadsheets entirely into memory. Each tile contains a packed representation of its cells:
for (tileIndex, tileInfo) in tableData.tiles.enumerated() {
guard let tile: TST_Tile = document.dereference(tileInfo.tile) else { continue }
for (rowIndex, rowInfo) in tile.rowInfos.enumerated() {
let actualRowIndex = tileIndex * Int(tile.numrows) + rowIndex
// Process cells in this row
try await processCellRow(
rowInfo: rowInfo,
rowIndex: actualRowIndex,
columnCount: Int(tableData.columnCount),
stringMap: tableData.stringMap,
richMap: tableData.richMap,
coordinateSpace: coordinateSpace,
tableModel: table
)
}
}Each cell’s data is packed into a binary structure starting with a 12-byte header:
Offset 0: Version (1 byte)
Offset 1: Cell type (1 byte)
Offset 2-5: Reserved
Offset 6-7: Extras (16-bit flags)
Offset 8-11: Storage flags (32-bit bitfield)The storage flags indicate which optional fields follow. A cell might have:
Decimal128 value (16 bytes)
Double value (8 bytes)
Timestamp in seconds (8 bytes)
String ID (4 bytes, indexes into string table)
Rich text ID (4 bytes, indexes into rich text table)
Cell style ID (4 bytes)
Text style ID (4 bytes)
Formula ID (4 bytes)
Various format IDs (4 bytes each)
The parser reads these sequentially based on which flags are set:
var dataOffset = offset + 12
if flags.contains(.hasDecimal128) {
if dataOffset + 16 <= buffer.count {
decimal128 = unpackDecimal128(from: buffer, offset: dataOffset)
dataOffset += 16
}
}
if flags.contains(.hasDouble) {
if dataOffset + 8 <= buffer.count {
double = buffer.withUnsafeBytes { bytes in
bytes.loadUnaligned(fromByteOffset: dataOffset, as: Double.self)
}
dataOffset += 8
}
}
// so on...Decimal128 values use a custom format with a bias constant for the exponent:
private func unpackDecimal128(from buffer: Data, offset: Int) -> Double {
let byte15 = UInt16(buffer[offset + 15])
let byte14 = UInt16(buffer[offset + 14])
let expBits = ((byte15 & 0x7F) << 7) | (byte14 >> 1)
let exp = Int(expBits) - IWorkConstants.decimal128Bias // Bias = 0x1820
var mantissa: UInt64 = UInt64(byte14 & 1)
for i in (0..<14).reversed() {
mantissa = mantissa * 256 + UInt64(buffer[offset + i])
}
let sign = (byte15 & 0x80) != 0
var value = Double(mantissa) * pow(10.0, Double(exp))
if sign {
value = -value
}
return value
}Cell borders require special handling. Rather than storing borders on individual cells (which would be wasteful), tables use stroke layers that define continuous border runs:
private func parseBorderForSide(
layers: [TSP_Reference],
row: Int,
column: Int,
isHorizontal: Bool
) -> Border? {
var bestBorder: (border: Border, order: Int)?
for layerRef in layers {
guard let strokeLayer: TST_StrokeLayerArchive = document.dereference(layerRef) else {
continue
}
for strokeRun in strokeLayer.strokeRuns {
let origin = Int(strokeRun.origin)
let length = Int(strokeRun.length)
let order = Int(strokeRun.order)
let intersects: Bool
if isHorizontal {
intersects = (layerIndex == row) && (column >= origin) && (column < origin + length)
} else {
intersects = (layerIndex == column) && (row >= origin) && (row < origin + length)
}
guard intersects else { continue }
let border = createBorderFromStroke(strokeRun)
// Higher order wins when strokes overlap
if bestBorder == nil || order > bestBorder!.order {
bestBorder = (border, order)
}
}
}
return bestBorder?.border
}This stroke layer system means a 1000x1000 table with full borders only needs to store 1000 horizontal stroke runs and 1000 vertical stroke runs, rather than 4 million border definitions.
Currency cells get special treatment with their own cell type and format information:
case CellType.currency.rawValue:
if let value = decimal128 ?? double, let format = currencyFormat {
return .currency(value, format: format, metadata: metadata)
}
return .emptyThe currency format includes the ISO 4217 code, decimal places (or 253 for automatic), whether to show the symbol, and whether to use accounting style (parentheses for negatives).
Fortunately, the computed values from cells containing formulas are cached in the document, so we don’t need an engine or separate formula parser.
Shapes and Vector Graphics
Shapes use a path system that supports multiple geometry types. The PathSource enum represents all possible shape types:
public enum PathSource {
case point(PointPathSource) // Arrows, stars, plus signs
case scalar(ScalarPathSource) // Rounded rectangles, polygons
case bezier(BezierPath) // Standard vector paths
case callout(CalloutPathSource) // Speech bubbles
case connectionLine(ConnectionLinePathSource) // Lines between shapes
case editableBezier(EditableBezierPathSource) // Paths with editable nodes
}Each type stores its geometry differently. Point-based shapes define their form through a single control point:
if pathSource.hasPointPathSource {
let pointSource = pathSource.pointPathSource
let type: PointPathSource.PointType
switch pointSource.type {
case .kTsdleftSingleArrow:
type = .leftSingleArrow
case .kTsdrightSingleArrow:
type = .rightSingleArrow
case .kTsddoubleArrow:
type = .doubleArrow
case .kTsdstar:
type = .star
case .kTsdplus:
type = .plus
}
return .point(
PointPathSource(
type: type,
point: PathPoint(x: Double(pointSource.point.x), y: Double(pointSource.point.y)),
naturalSize: CGSize(
width: CGFloat(pointSource.naturalSize.width),
height: CGFloat(pointSource.naturalSize.height)
)
))
}Bezier paths store sequences of path elements (moveTo, lineTo, curveTo, closeSubpath):
let elements = bezierSource.path.elements.map { element -> PathElement in
let type: PathElementType
switch element.type {
case .moveTo:
type = .moveTo
case .lineTo:
type = .lineTo
case .quadCurveTo:
type = .quadCurveTo
case .curveTo:
type = .curveTo
case .closeSubpath:
type = .closeSubpath
}
let points = element.points.map { point in
PathPoint(x: Double(point.x), y: Double(point.y))
}
return PathElement(type: type, points: points)
}Shapes can contain text; they have an optional ownedStorage field referencing a text storage. Text boxes are just shapes with specific styling.
Charts
Charts combine multiple systems: data grids, axes, series styling, and legends. The chart grid stores values in a row/column structure with a direction flag indicating whether series run by row or by column:
let rows = grid.gridRow.map { gridRow in
let values = gridRow.value.map { tschValue -> ChartGridValue in
if tschValue.hasNumericValue {
return .number(tschValue.numericValue)
}
if tschValue.hasDateValue {
return .date(tschValue.dateValue)
}
if tschValue.hasDurationValue {
return .duration(tschValue.durationValue)
}
return .empty
}
return ChartGridRow(values: values)
}Each axis gets its own style and non-style archives. The style archive controls visual appearance (visibility, colors, line widths). The non-style archive controls data properties (minimum/maximum values, number formats, scale type):
if let firstNonStyleRef = axisNonStyles.first,
let axisNonStyle = document.dereference(firstNonStyleRef) as? TSCH_ChartAxisNonStyleArchive {
let props = axisNonStyle.TSCH_Generated_ChartAxisNonStyleArchive_current
if isValueAxis {
if props.hasTschchartaxisdefaultusermin,
props.tschchartaxisdefaultusermin.hasNumberArchive {
minimumValue = props.tschchartaxisdefaultusermin.numberArchive
}
if props.hasTschchartaxisdefaultusermax,
props.tschchartaxisdefaultusermax.hasNumberArchive {
maximumValue = props.tschchartaxisdefaultusermax.numberArchive
}
}
}Series get individual styling, allowing mixed chart types (a bar series and a line series on the same chart):
for seriesIndex in 0..<seriesCount {
let seriesType = parseChartType(from: chart)
var fill: ShapeFill = .none
var stroke: Border?
if let style = seriesStyle {
let props = style.TSCH_Generated_ChartSeriesStyleArchive_current
switch seriesType {
case .bar2D, .bar3D:
if props.hasTschchartseriesbarfill {
fill = parseShapeFill(from: props.tschchartseriesbarfill)
}
case .line2D, .line3D:
if props.hasTschchartserieslinestroke {
stroke = createBorderFromStroke(props.tschchartserieslinestroke)
}
// ... more series types
}
}
}Style Inheritance and Resolution
Every styled element (paragraphs, characters, cells, shapes) uses an inheritance chain. A paragraph style references its parent style, which references its parent, forming a chain from the default style up to the specific overrides:
static func buildParagraphStyleChain(
_ style: TSWP_ParagraphStyleArchive?,
document: IWorkDocument
) -> [TSWP_ParagraphStyleArchive] {
guard let style = style else { return [] }
var chain: [TSWP_ParagraphStyleArchive] = []
var current: TSWP_ParagraphStyleArchive? = style
while let s = current {
chain.append(s)
if s.super.hasParent,
let parentRef = s.super.parent as TSP_Reference?,
let parent = document.dereference(parentRef) as? TSWP_ParagraphStyleArchive {
current = parent
} else {
current = nil
}
}
return chain.reversed() // Root to leaf
}Properties resolve by walking the chain from root to leaf, with later styles overriding earlier ones:
for style in chain {
let props = style.paraProperties
if props.hasAlignment {
alignment = StyleConverters.convertTextAlignment(props.alignment)
}
if props.hasLeftIndent {
leftIndent = Double(props.leftIndent)
}
// ... more properties
}Spatial Information and Reading Order
Every positioned element includes complete spatial information: frame, rotation, z-index, and coordinate space. This matters because iWork documents use an infinite canvas model; elements can be anywhere, overlapping and rotated freely.
When converting to linear formats like Markdown or analyzing document structure, we need to establish a natural reading order. For Keynote slides and Numbers sheets, we sort drawables by spatial position (top-to-bottom, then left-to-right)2:
private func sortDrawablesByPosition(_ drawables: [TSP_Reference]) -> [TSP_Reference] {
return drawables.sorted { refA, refB in
guard let drawableA = document.dereference(refA),
let drawableB = document.dereference(refB) else {
return false
}
let frameA = parseFrameFromDrawable(drawableA)
let frameB = parseFrameFromDrawable(drawableB)
let centerYA = frameA.midY
let centerYB = frameB.midY
if centerYA != centerYB {
return centerYA < centerYB
}
return frameA.midX < frameB.midX
}
}This produces text that reads naturally rather than jumping around the canvas randomly. For Pages documents, we separate inline content (flows with text) from floating content (positioned absolutely), processing them in separate passes.

The Visitor Protocol
Rather than exposing the raw protobuf structure, the parser uses a visitor pattern. Implementing the IWorkDocumentVisitor protocol gives you callbacks for each document element in traversal order:
public protocol IWorkDocumentVisitor {
func willVisitDocument(type: IWorkDocument.DocumentType,
layout: DocumentLayout?,
pageSettings: PageSettings?) async
func willVisitParagraph(style: ParagraphStyle, spatialInfo: SpatialInfo?) async
func visitInlineElement(_ element: InlineElement) async
func didVisitParagraph() async
func willVisitTable(name: String?,
rowCount: UInt32,
columnCount: UInt32,
spatialInfo: SpatialInfo) async
func visitTableCell(row: Int, column: Int, content: TableCellContent) async
func didVisitTable() async
func visitImage(info: ImageInfo,
spatialInfo: SpatialInfo,
ocrResult: OCRResult?,
hyperlink: Hyperlink?) async
// ...
}All inline elements within a paragraph arrive through a single method in document order:
func visitInlineElement(_ element: InlineElement) async {
switch element {
case .text(let text, let style, let hyperlink):
// Process text run
case .image(let info, let spatialInfo, let ocrResult, let hyperlink):
// Process inline image
case .footnoteMarker(let footnote):
// Process footnote reference
// ...
}
}This preserves the exact reading order: text before shape, shape content, text after shape. You don’t need to manually reconstruct the sequence from separate arrays and position calculations.
The visitor receives fully resolved styles (inheritance chains already processed), decoded table cells (binary format already parsed), and proper coordinate transformations (mask transforms already calculated). The end results of which I’m very happy with.
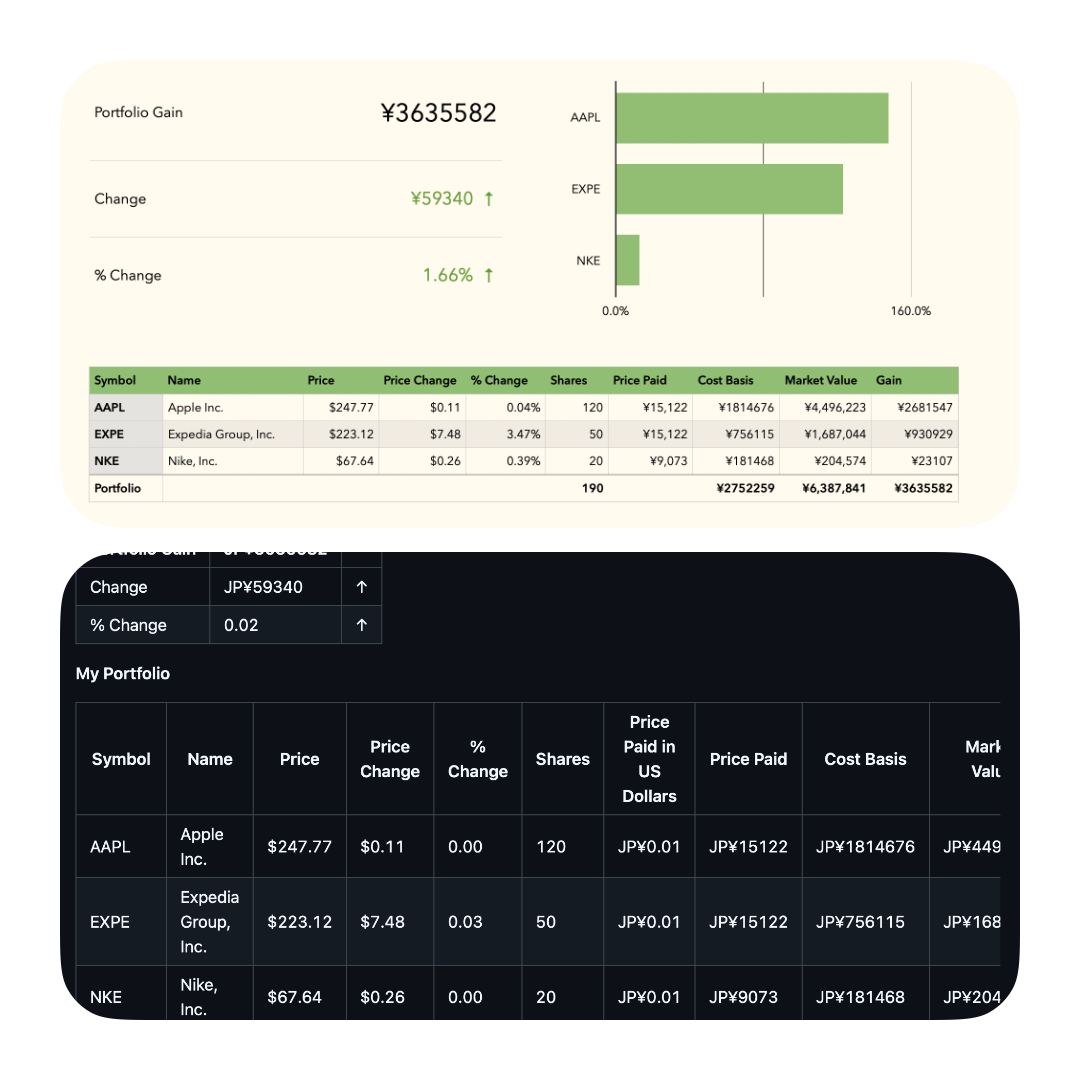
And just to further validate the spacial information, I wrote a naive PDF visitor to export an iWork document to PDF:

Wrapping up
All the code discussed here is available as a Swift package at github.com/6over3/WorkKit. The repository includes the protobuf schema extraction tools, type mapping generators, and the full parser implementation. Documentation covers the visitor protocol and common use cases.
A few areas aren’t implemented yet: the legacy (A)XML format, formula evaluation, and some of the more obscure shape types. Pull requests welcome if you need these features. I believe this is the only real parser for iWork to-date.
As an aside, I think I’ll be moving off Substack for technical articles like this. I wanted this post have interactive elements, but Substack is not suited for this type of content.
I’ve uploaded to official programming guide for AXML to Archive.org
I was initially this might have a bias for documents produced in the west, but after testing on a few Japanese presentations I was happy with the results.
Impressive work. Just one question: Are you sure Affero GPL 3.0 is the license you want to use for this? (Just say "absolutely" if so, I am not interested in starting a discussion about the pros and cons of various Open Source licenses...)
I’m impressed. Maybe Apple should offer you a job.